Run detail
Subject 2-M16 — Deployment Run 2026-03-19
Date: 2026-03-19
Run note
The featured public 2-M16 bundle uses the March 19 checkpoint with the May 2026 per-finger actuation path: high command precision, low false REST actuation, and event-level responsiveness are reported separately from offline accuracy.
Highlights
- Current cleaned-corpus replay precision is 95.37% among non-rest would-send command windows.
- False REST actuation is 0.25%, or 6 movement commands over 2,404 true REST replay windows.
- Event hit rate is 91.11% across 596 movement events, with first-hit latency of 82 ms median and 377 ms p95.
- The 31.56% window-level send coverage is a throughput metric, not a classifier accuracy metric or a ceiling on event responsiveness.
Changes in this bundle
- Command shaping now treats the 250 ms hold as same-finger state retention rather than a global cooldown.
- Other fingers can actuate during that hold interval when their gated commands are stable.
- The public metrics replace the old 10.57% global-gate send recall with current per-finger precision, throughput coverage, event hit rate, and latency.
- The April 24 model-selection audit remains as historical comparison context; it is no longer the current deployment-metric headline.
Deployment note
Selection is ranked for public deployment behavior first: precision, event hit rate, latency, false REST actuation, and valid command pairs. Offline holdout accuracy remains a separate model-quality metric.
Frozen live defaults
Postprocess enabled, ema (5), finger_mode=raw
threshold_action=0.05, threshold_finger=0.2, threshold_applicability=0.4, actuation_min_prob=0.2
actuation_stability=3, hold_ms=250, hold_scope=same_finger, command_rate_hz=20, speed_modulation=on
Test action accuracy
89.79%
2,301 held-out windows
Finger accuracy on non-rest
85.96%
1,994 non-rest test windows
Primary holdout joint accuracy
84.66%
Rest TPR 98.37% · applicability FN 2.26%
Event-level joint accuracy
87.60%
121 held-out events · action 92.56%
Pseudo-live committed joint
86.42%
Would-send precision 95.37% · event hit 91.11% · false rest actuation 0.25%
Why this run is displayed
The March 19 checkpoint now ships with per-finger actuation defaults.
The trained checkpoint is still 20260319_075520. The public deployment bundle has been updated around it: same-finger holds prevent command chatter, other fingers can still actuate immediately, and the public metrics now report throughput separately from accuracy.
95.37%
Would-send precision
Among non-rest windows that passed the current per-finger actuation gate, 95.37% carried the correct movement command.
0.25%
False rest actuation
Only 6 of 2,404 true REST replay windows produced a movement command under the current defaults.
91.11%
Event hit rate
The replay hit 543 of 596 movement events at least once, which is the better responsiveness summary than window-level send coverage.
2,595 configs
Postprocess ablation
The March 16, 2026 website update documents a 2,595-config ablation over thresholds, smoothing, hysteresis, adjacency, and finger-mode settings.
How this run was chosen
- The public bundle still uses the March 19 checkpoint because it combines strong held-out decoding with the safest validated deployment behavior.
- The May 2026 replay uses the corrected per-finger hold semantics: a finger holds its last command briefly, but other fingers are not globally blocked.
- The old 10.57% would-send recall was a global-gate throughput number. It should not be read as a 10.57% accuracy ceiling.
- A future replacement should beat the current bundle on precision, event hit rate, latency, and false REST actuation, not only on offline holdout accuracy.
How the tuning campaign evolved
- The February 26, 2026 update documents the earlier large-scale weight and hyperparameter campaign: 100+ trained variants, a 30+ hour sweep, and a largest logged 90-run block.
- The March 16, 2026 update documents the later deployment-facing postprocess ablation that froze the live default family after 2,595 evaluated configurations.
- The March 18, 2026 update widened the selection criteria from holdout accuracy alone to include full-session replay, pseudo-live behavior, and the end-to-end Step 7 control path.
- The May 6 replay update keeps March 19 as the displayed checkpoint and replaces the old global cooldown interpretation with per-finger actuation metrics.
Training Recipe & Frozen Runtime
This is the deeper layer behind the public bundle: the training recipe, split policy, auxiliary data support, and frozen deployment defaults that carried the winning checkpoint into replay and pseudo-live evaluation.
Training stack
Architecture
CNNLSTMFingerActionNet
The March 19 checkpoint combines action decoding, active-finger decoding, and a dedicated finger-applicability head.
Optimization
60 epochs · batch 64 · lr 0.001 · seed 43
These values come from the restored March 19 deployment metrics bundle.
Split policy
group_trial · test_size 0.2 · calibration_size 0.1
The holdout bundle stays tied to a fixed split while calibration is separated from the main train/test partition.
Input + preprocessing
64 x 4 windows · center_detrend
Per-window centering and detrending are frozen into the reference run's preprocessing and normalizer config.
Sampler
cleaned March 19 corpus
The deployment run uses the cleaned combined corpus with the problematic rest events pruned from the February 16 session.
Rest support
1,059 auxiliary quiet-rest windows
The auxiliary quiet-rest session is used for train-only support while the core split contributes 11,388 windows and the public test split contributes 2,301 windows.
Replay and runtime stack
Frozen live defaults
EMA · action 0.05 · finger 0.20 · applicability 0.40
The March 19 displayed metrics use the tuned postprocess family instead of the April 3 raw-gated replay path.
Actuation gates
min_prob 0.2 · stability 3 · same-finger hold 250 ms
The hold suppresses rapid flips on the same finger while allowing other fingers to actuate during that interval.
Replay cadence
0.25 s windows · 0.05 s hop
The pseudo-live replay runs the same checkpoint through the saved inference and actuation path at a replay cadence close to live use.
Cleaned replay accuracy
86.42% committed joint
This is the committed action-plus-finger score on the cleaned pseudo-live corpus; first-send timing is reported separately.
Would-send onset
0.083 s median · 0.377 s p95
Event-relative first-send timing is tracked alongside the precision and rest-safety metrics used for model selection.
Replay footprint
12,447 cleaned windows
The cleaned deployment replay uses the combined March 19 corpus, giving a broader check than the 2,301-window saved test split.
Key Metrics
The public headline metrics use the published holdout bundle. Extended evaluation cards below add replay and pseudo-live context so the reader can see how the model behaves beyond a single split.
| Split | Metric | Value |
|---|---|---|
| Train | Action accuracy | 86.39% |
| Train | Finger accuracy | 86.80% |
| Train | Avg loss | 0.7714 |
| Train | Config | epochs=60, batch=64, lr=0.001, seed=43 |
| Test | Action accuracy | 89.79% |
| Test | Finger accuracy on non-rest windows | 85.96% |
| Test | Joint accuracy | 84.66% |
| Test | Joint accuracy on non-rest | 82.55% |
| Event | Action accuracy by majority vote | 92.56% |
| Event | Joint accuracy by majority vote | 87.60% |
| Event | Finger accuracy on non-rest events | 90.68% |
| Event | Events scored | 121 total / 118 non-rest |
| Test | Finger accuracy overall | 87.61% |
| Test | Rest TPR / precision / F1 | 98.37% / 80.11% / 0.883 |
| Test | Rest FPR | 3.76% |
| Test | Applicability FP / FN | 18.57% / 2.26% |
| Test | Action-applicability disagreement | 3.56% |
| Test | Raw valid / invalid pair rate | 83.62% / 16.38% |
| Test | Raw non-rest NONE / raw rest active-finger | 0.00% / 16.38% |
| Test | Committed non-rest NONE / committed rest active-finger | 0.00% / 0.00% |
| Test | Action ECE / finger ECE on non-rest | 2.32% / 2.73% |
| Test | Deployment pair invariant | passed |
| Test | Test windows | 2,301 |
| Test | Non-rest test windows | 1,994 |
Artifacts
model=finger_action_model.pt, scaler=scaler.npz, preds=test_predictions.npz
temperature scaling=temperature_scaling.json
Source identifiers: subject=2-M16, session=combined_20260319_081200_pruned_rest_events_0_1_2, run=20260319_075520
Created UTC: 2026-03-19T08:27:08+00:00
How to read this bundle
The test row is the saved split summary. Replay and pseudo-live cards below use the same checkpoint under different evaluation conditions.
Action train-test gap: 3.39%, with test accuracy slightly higher than training accuracy.
Quick Per-Event Accuracy
Majority vote by (session_id,event_id) over primary holdout windows; committed predictions map REST to NONE before scoring.
By action
| Action | Events | Action | Joint |
|---|---|---|---|
| REST | 3 | 100.00% | 100.00% |
| OPEN | 57 | 92.98% | 82.46% |
| CLOSE | 61 | 91.80% | 91.80% |
By non-rest finger
| Finger | Events | Finger | Joint |
|---|---|---|---|
| THUMB | 24 | 100.00% | 100.00% |
| INDEX | 22 | 100.00% | 90.91% |
| MIDDLE | 26 | 76.92% | 76.92% |
| RING | 21 | 80.95% | 71.43% |
| PINKY | 25 | 96.00% | 96.00% |
Extended Evaluation
This section groups repeated splits, quiet-rest replay, and chronological replay for the same run.
Auxiliary quiet-rest benchmark
Target: 2-M16_20260315_145838_01
Windows: 1,059
Action accuracy: 97.26%
Rest TPR: 97.26%
Rest precision: 100.00%
Rest F1: 0.986
Applicability FP on true rest: 4.53%
Deployment pair invariant: passed
Dedicated quiet-rest replay used to measure rest-side applicability false positives on true rest windows.
Core full-session replay
Target: 2-M16_20260216_150056_01 + 2-M16_20260317_190134
Windows: 11,388
Action accuracy: 88.48%
Joint accuracy: 84.30%
Joint accuracy on non-rest: 82.73%
Finger accuracy on non-rest: 85.71%
Rest TPR: 95.99%
Rest precision: 69.15%
Applicability FP on true rest: 18.07%
Applicability FN on true non-rest: 3.68%
Committed non-rest + NONE rate: 0.00%
Committed rest + active-finger rate: 0.00%
Deployment pair invariant: passed
Chronological replay across the two core movement sessions with zero committed pair leakage and explicit applicability diagnostics.
Pseudo-Live Replay
Pseudo-live replay runs the saved EEG windows through the Step 7 decision path and records what the hand would have done without contacting hardware. This is the closest public benchmark on the site to live control behavior.
Pseudo-live replay on the cleaned deployment corpus with per-finger actuation
Target: combined_20260319_081200_pruned_rest_events_0_1_2
Training source: March 19 checkpoint with May 2026 per-finger command shaping
Windows: 12,447
Committed action accuracy: 91.50%
Committed joint accuracy: 86.42%
Committed finger accuracy on non-rest: 85.51%
Applicability FP on true rest: 12.10%
Applicability FN on true non-rest: 3.68%
Would-send precision on non-rest: 95.37%
Would-send throughput coverage on non-rest: 31.56%
False rest actuation rate: 0.25%
False rest actuation count: 6 of 2,404 true REST windows
Event hit rate: 91.11% across 596 events
First-hit latency median / p95: 0.083 s / 0.377 s
Non-rest NONE count: 0
Committed non-rest + NONE rate: 0.00%
Committed rest + active-finger rate: 0.00%
Sent non-rest + NONE rate: 0.00%
Sent rest + active-finger rate: 0.00%
Deployment pair invariant: passed
Current replay uses same-finger hold semantics: a finger keeps its last command briefly, while other fingers can still actuate. The 31.56% window-level value is throughput coverage, not classification accuracy.
Pseudo-live replay on the legacy combined corpus
Target: combined_20260317_211414
Training source: Winning March 19 deployment checkpoint
Windows: 12,969
Committed action accuracy: 87.95%
Committed joint accuracy: 82.98%
Committed finger accuracy on non-rest: 85.90%
Applicability FP on true rest: 27.79%
Applicability FN on true non-rest: 3.68%
Would-send precision on non-rest: 89.62%
Would-send throughput coverage on non-rest: 10.57%
False rest actuation rate: 1.71%
Non-rest NONE count: 0
Committed non-rest + NONE rate: 0.00%
Committed rest + active-finger rate: 0.00%
Sent non-rest + NONE rate: 0.00%
Sent rest + active-finger rate: 0.00%
Deployment pair invariant: passed
First-send latency median / p95: 0.083 s / 0.317 s
Regression replay against the pre-pruned March 17 combined corpus.
Pseudo-live replay on the March 17 realism session
Target: 2-M16_20260317_190134
Training source: Winning March 19 deployment checkpoint
Windows: 1,644
Committed action accuracy: 72.87%
Committed joint accuracy: 71.96%
Committed finger accuracy on non-rest: 9.72%
Applicability FP on true rest: 17.89%
Applicability FN on true non-rest: 52.98%
Would-send precision on non-rest: 62.50%
Would-send throughput coverage on non-rest: 0.99%
False rest actuation rate: 0.09%
Non-rest NONE count: 0
Committed non-rest + NONE rate: 0.00%
Committed rest + active-finger rate: 0.00%
Sent non-rest + NONE rate: 0.00%
Sent rest + active-finger rate: 0.00%
Deployment pair invariant: passed
First-send latency median / p95: 0.381 s / 0.566 s
Hard realism check remains conservative: pair invariants hold, but applicability recall is still weak on this session.
Across published runs
Compare to other runs
Finger accuracy is reported on non-rest windows only.
| Run | Date | Action accuracy | Finger accuracy on non-rest windows | Test windows |
|---|---|---|---|---|
| 2-m16 | 2026-03-19 | 89.79% | 85.96% | 2,301 |
| 1-m16-500 | 2026-03-05 | 83.94% | 80.61% | 2,652 |
Plain-language highlights
- Test action accuracy: 89.79%.
- Test finger accuracy on non-rest windows: 85.96%.
- Event-level joint accuracy: 87.60%.
- Pseudo-live command precision: 95.37%.
- Pseudo-live send coverage: 31.56% throughput, not accuracy.
- Pseudo-live event hit rate: 91.11%.
- Test windows: 2,301.
What this means
- Action accuracy measures how often held-out EEG windows were assigned the correct REST, OPEN, or CLOSE label.
- Finger accuracy on non-rest windows isolates finger classification after removing EEG windows labeled rest.
- Event-level accuracy groups overlapping windows by event and scores the majority prediction for each held-out event.
- Pseudo-live send coverage is a deployment throughput metric; it should not be read as held-out classifier accuracy.
- These are EEG-window-level metrics and should not be interpreted as direct trial-level or online-control performance.
- Confusion matrices and confidence plots provide error structure that is not visible from accuracy alone.
Trust & Caveats
- The public metrics bundle does not include full per-class counts, so class imbalance is not fully characterized on-page.
- The pipeline uses overlapping windows; leakage control depends on split settings and metadata quality.
- This public bundle does not expose run-specific split mode or purge settings, so leakage risk cannot be fully ruled out for this run.
Topomaps & Signal Evidence
These alpha-band topomaps are here to show what changed physiologically, not to replace the classifier metrics. They help explain why the current deployment strategy leans on lateral Muse 2 channels and cleaned multi-session training rather than a narrow single-session fit.
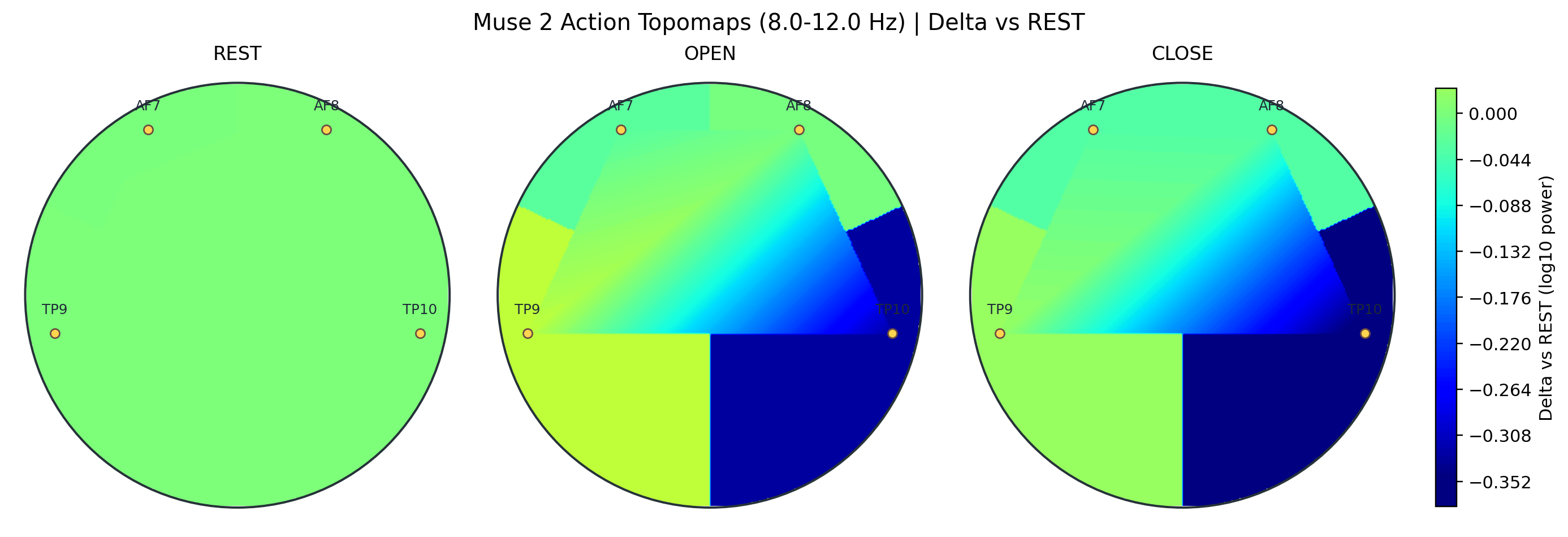
Action alpha rest-delta topomap
Rest-relative alpha maps for REST, OPEN, and CLOSE in the March 19 winning session. OPEN and CLOSE both show the dominant TP10 decrease and smaller TP9 increase that characterize the current 2-M16 action story.
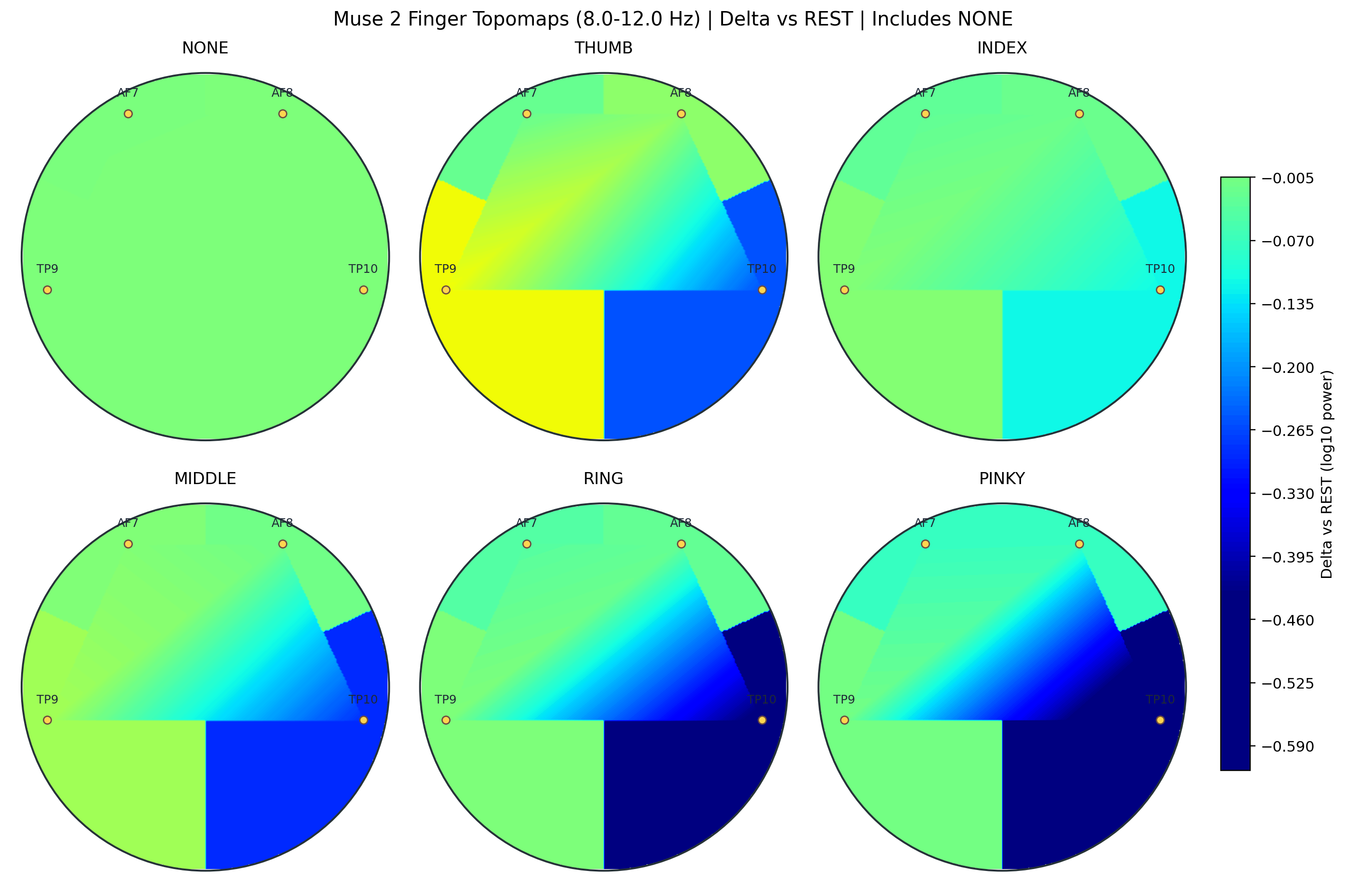
Finger alpha rest-delta topomap with NONE reference
Finger-level rest-delta maps, including NONE as the explicit rest reference. The strongest variation remains concentrated on TP10 and TP9, which helps explain why lateral Muse 2 channels carry most of the finger-separation load.
Interpretive notes
- The strongest rest-relative separations remain concentrated on the lateral Muse 2 channels rather than a broad scalp-wide shift.
- OPEN and CLOSE are highly similar in rest-relative alpha topography, so these figures are best read as signal-evidence context rather than a substitute for temporal decoding metrics.
- Finger-level variation remains strongest on TP10 and then TP9, with AF7 and AF8 changing much less.
Figures
These figures carry the structure behind the headline metrics. The confusion matrices show where the decoder drifts, while the confidence panels show whether the model's probabilities are stable enough to support conservative actuation rules.
Note: in the finger confusion matrix, rest action misses are shown as NONE. Those cells reflect true movement windows that the action head labeled rest, not deployable OPEN/CLOSE plus NONE outputs.
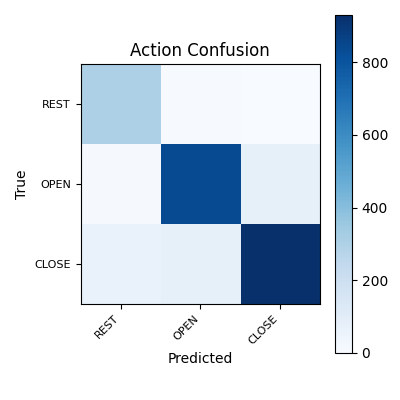
Action confusion matrix
Confusion matrix for action classification across REST, OPEN, and CLOSE. Rows show the actual labels, columns show the predicted labels, and off-diagonal cells show where action boundaries remain unstable.
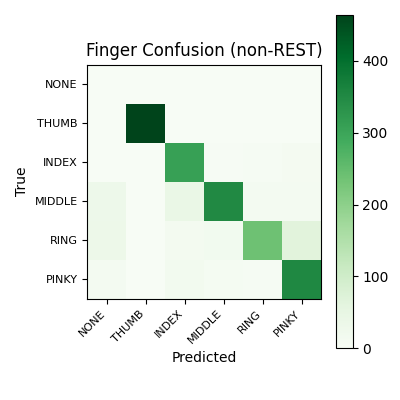
Finger confusion matrix on non-rest windows
Confusion matrix for finger classification on non-rest windows. The diagonal shows which active fingers remain separable after rest is removed from the task.
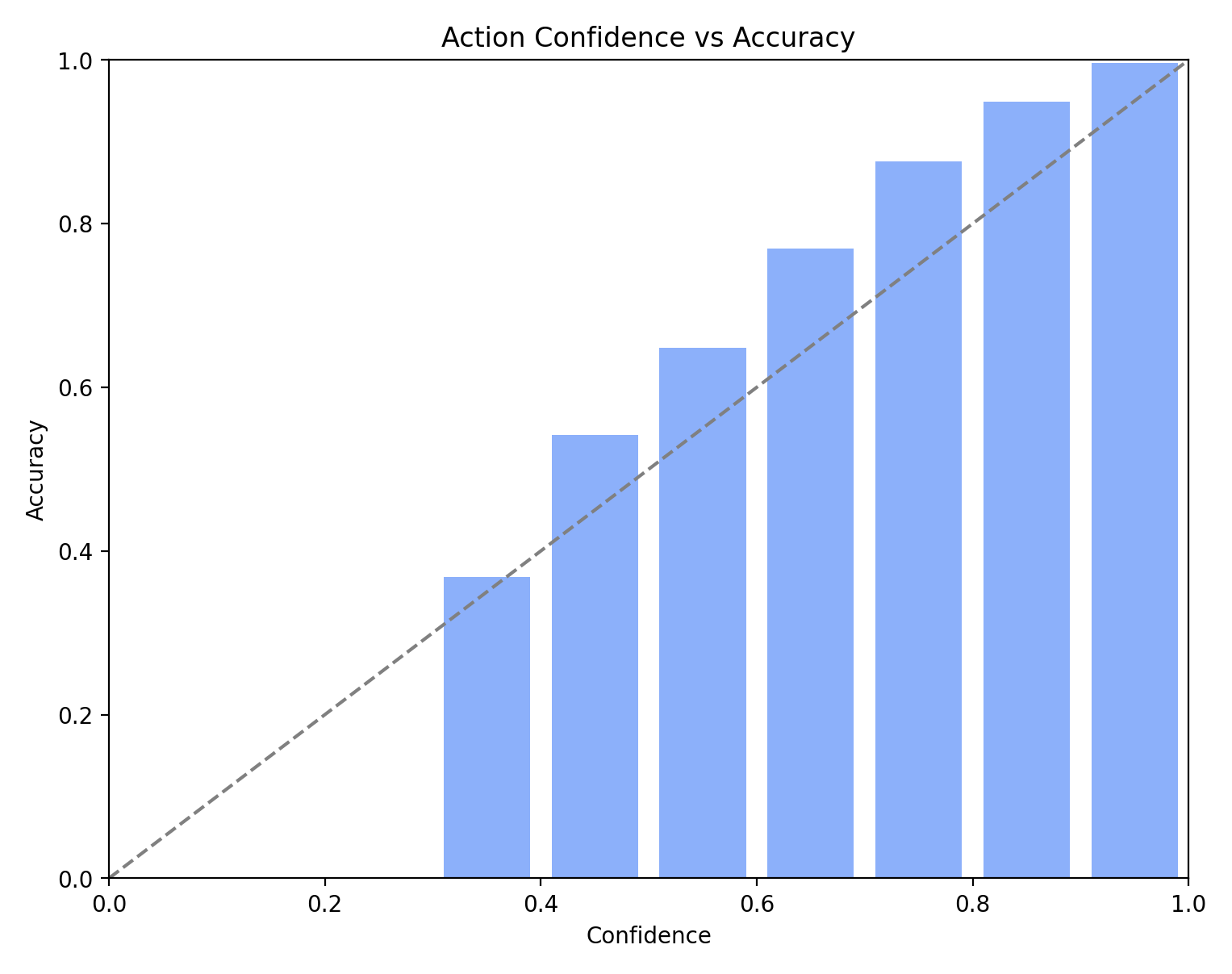
Action calibration
Action calibration helps show whether confidence tracks observed correctness tightly enough to support conservative actuation gates and replay analysis.
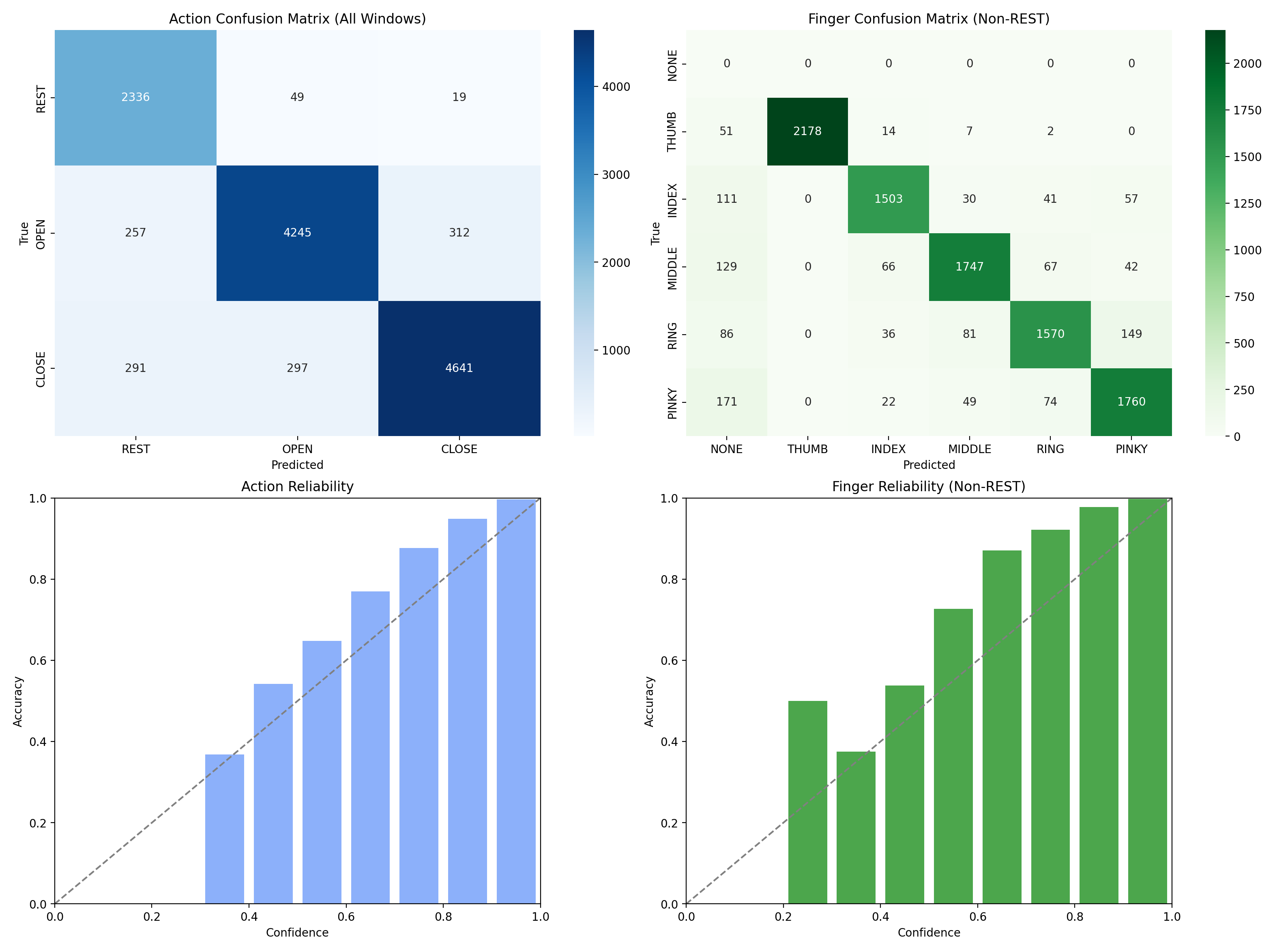
Holdout evaluation summary
The reference evaluation summary combines action and finger confusion matrices with reliability diagrams so accuracy and confidence can be read together.
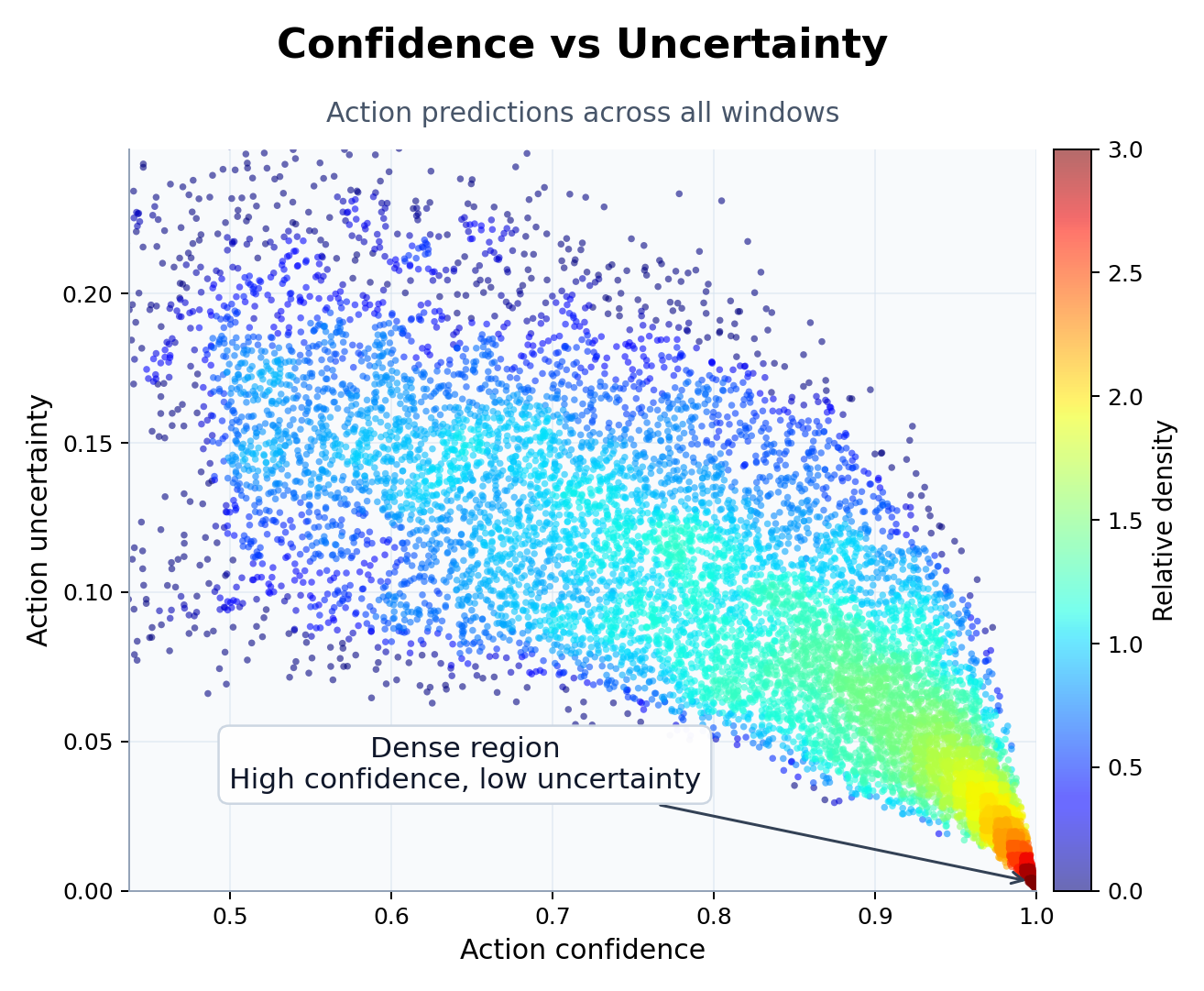
Confidence and uncertainty scatter
The uncertainty scatter shows where action predictions stay compact and where they begin to loosen. High-confidence, low-uncertainty regions are the most stable part of the decoding space.
Source trail
Follow the selection path
These links document how the project moved from broad tuning and ablation work to the current public run.
Per-finger actuation update
May 6, 2026 update replacing the old global cooldown interpretation with current throughput and event-hit metrics.
Rollback audit
April 24, 2026 model-selection audit comparing March 19 and April 3 with concrete rankings.
Live-inference diagnosis
April 29, 2026 follow-up documenting the April 28 same-sitting replay failure and the added preflight requirements.
Winning-model update
March 19, 2026 refresh for the restored featured deployment candidate.
Deployment breakthrough update
March 18, 2026 post that expands the selection story to replay and pseudo-live behavior.
Split-fix and live-defaults update
March 16, 2026 post documenting the 2,595-config postprocess ablation.
Older tuning update
February 26, 2026 tuning post documenting 100+ model variants, a 30+ hour sweep, and the 90-run / 33.3-hour logged block.
HTML report
Full report bundle for the current public run.
Metrics JSON
Sanitized metrics bundle for the current public run.