Run detail
Subject 1-M16 — Run 2026-03-05
Date: 2026-03-05
Legacy baseline note
The published 1-M16 bundle is retained for historical context, but it was produced with earlier methods and a legacy model. Its metrics should therefore be interpreted cautiously and not treated as a direct comparison against the current 2-M16 bundle.
Test action accuracy
83.94%
2,652 held-out windows
Finger accuracy on non-rest
80.61%
2,538 non-rest test windows
Primary holdout joint accuracy
N/A
Rest TPR N/A · applicability FN N/A
Event-level joint accuracy
N/A
N/A held-out events · action N/A
Pseudo-live committed joint
N/A
Would-send precision N/A · event hit N/A · false rest actuation N/A
Historical context
This run stays on the site as a baseline, not as the deployment story.
The 1-M16 bundle is still useful because it shows a second subject, an earlier tuning cycle, and the kind of metrics that were available before the broader March 2026 evaluation push. It is not the model-selection path that produced the current featured 2-M16 run.
2026-02-27 refresh
Published tuning checkpoint
The website's February 27, 2026 update documents a tuned 1-M16 rerun and compares it against the February 21 baseline.
Historical baseline
Earlier methods stack
Later March updates explicitly warn that 1-M16 used earlier methods and should not be treated as a direct comparison to the current 2-M16 deployment stack.
60 epochs
Published training budget
The public bundle preserves the core training budget: 60 epochs, batch size 64, learning rate 0.001, and seed 45.
How this run was chosen
- This bundle is retained to show a second subject and a real historical checkpoint rather than a hand-picked retrospective summary.
- It is useful for context on subject-to-subject variation, but it was not chosen as the current featured path.
- The right way to read this page is as baseline evidence, not as the final architecture or tuning recipe.
How the tuning campaign evolved
- The February 27, 2026 tuning update focused on weight changes, split settings, and expanded diagnostics rather than the larger replay ladder that came later for 2-M16.
- That update improved action accuracy relative to the earlier 1-M16 baseline, but the finger tradeoff remained mixed.
- For this reason, the bundle remains informative but historically bounded.
Training Recipe & Frozen Runtime
This is the deeper layer behind the public bundle: the training recipe, split policy, auxiliary data support, and frozen deployment defaults that carried the winning checkpoint into replay and pseudo-live evaluation.
Training stack
Optimization
60 epochs · batch 64 · lr 0.001 · seed 45
These values come from the public training metrics bundle for 1-M16.
Published split
2,652 test windows · 2,538 non-rest
Finger accuracy is reported on non-rest windows only so the active-finger score stays tied to movement windows.
Train profile
83.35% action · 85.38% finger · 0.7331 avg loss
This summarizes the saved training-side metrics for the retained public checkpoint.
Role on site
Legacy baseline
This run is deliberately kept visible to show the earlier state of the project before the March 2026 deployment-candidate work.
Replay and runtime stack
Public artifacts
Metrics JSON · confusion matrices · calibration plots · HTML report
The baseline bundle still exposes the same viewer-facing artifacts even though its evaluation story is shallower than the current 2-M16 run.
Interpretation rule
Window-level offline evidence
This run should be interpreted as an offline window-level result bundle, not as the live or pseudo-live story used to justify the newer featured run.
Key Metrics
The public headline metrics use the published holdout bundle. Extended evaluation cards below add replay and pseudo-live context so the reader can see how the model behaves beyond a single split.
| Split | Metric | Value |
|---|---|---|
| Train | Action accuracy | 83.35% |
| Train | Finger accuracy | 85.38% |
| Train | Avg loss | 0.7331 |
| Train | Config | epochs=60, batch=64, lr=0.001, seed=45 |
| Test | Action accuracy | 83.94% |
| Test | Finger accuracy on non-rest windows | 80.61% |
| Test | Joint accuracy | N/A |
| Test | Joint accuracy on non-rest | N/A |
| Test | Finger accuracy overall | N/A |
| Test | Rest TPR / precision / F1 | N/A / N/A / N/A |
| Test | Rest FPR | N/A |
| Test | Applicability FP / FN | N/A / N/A |
| Test | Action-applicability disagreement | N/A |
| Test | Raw valid / invalid pair rate | N/A / N/A |
| Test | Raw non-rest NONE / raw rest active-finger | N/A / N/A |
| Test | Committed non-rest NONE / committed rest active-finger | N/A / N/A |
| Test | Action ECE / finger ECE on non-rest | N/A / N/A |
| Test | Deployment pair invariant | failed |
| Test | Test windows | 2,652 |
| Test | Non-rest test windows | 2,538 |
Artifacts
model=finger_action_model.pt, scaler=scaler.npz, preds=test_predictions.npz
Source identifiers: subject=1-M16, session=1-M16_20260216_123857_01, run=20260305_052744
Created UTC: 2026-03-05T05:31:31.690887+00:00
How to read this bundle
The test row is the saved split summary. Replay and pseudo-live cards below use the same checkpoint under different evaluation conditions.
Action train-test gap: 0.58%, with test accuracy slightly higher than training accuracy.
Across published runs
Compare to other runs
Finger accuracy is reported on non-rest windows only.
| Run | Date | Action accuracy | Finger accuracy on non-rest windows | Test windows |
|---|---|---|---|---|
| 2-m16 | 2026-03-19 | 89.79% | 85.96% | 2,301 |
| 1-m16-500 | 2026-03-05 | 83.94% | 80.61% | 2,652 |
Plain-language highlights
- Test action accuracy: 83.94%.
- Test finger accuracy on non-rest windows: 80.61%.
- Test windows: 2,652.
What this means
- Action accuracy measures how often held-out EEG windows were assigned the correct REST, OPEN, or CLOSE label.
- Finger accuracy on non-rest windows isolates finger classification after removing EEG windows labeled rest.
- These are EEG-window-level metrics and should not be interpreted as direct trial-level or online-control performance.
- Confusion matrices and confidence plots provide error structure that is not visible from accuracy alone.
Trust & Caveats
- The public metrics bundle does not include full per-class counts, so class imbalance is not fully characterized on-page.
- This run reflects an earlier model and legacy evaluation methods, so its published numbers should be treated as a historical baseline rather than a directly comparable benchmark against the current 2-M16 deployment stack.
- The pipeline uses overlapping windows; leakage control depends on split settings and metadata quality.
- This public bundle does not expose run-specific split mode or purge settings, so leakage risk cannot be fully ruled out for this run.
Figures
These figures carry the structure behind the headline metrics. The confusion matrices show where the decoder drifts, while the confidence panels show whether the model's probabilities are stable enough to support conservative actuation rules.
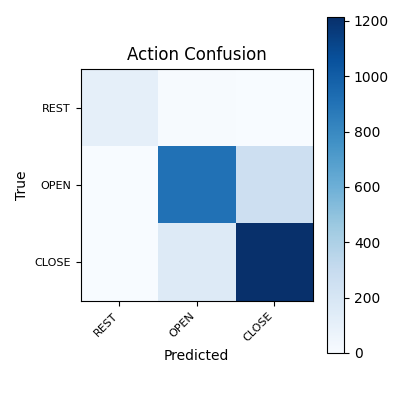
Action confusion matrix
Confusion matrix for action classification across REST, OPEN, and CLOSE. Rows show the actual labels, columns show the predicted labels, and off-diagonal cells show where action boundaries remain unstable.
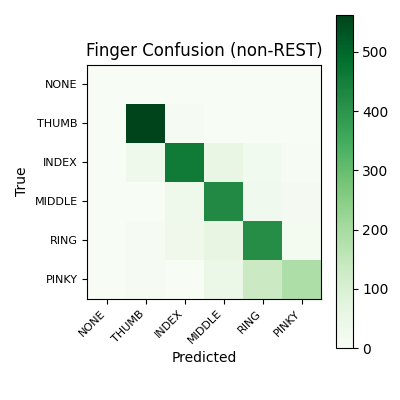
Finger confusion matrix on non-rest windows
Confusion matrix for finger classification on non-rest windows. The diagonal shows which active fingers remain separable after rest is removed from the task.
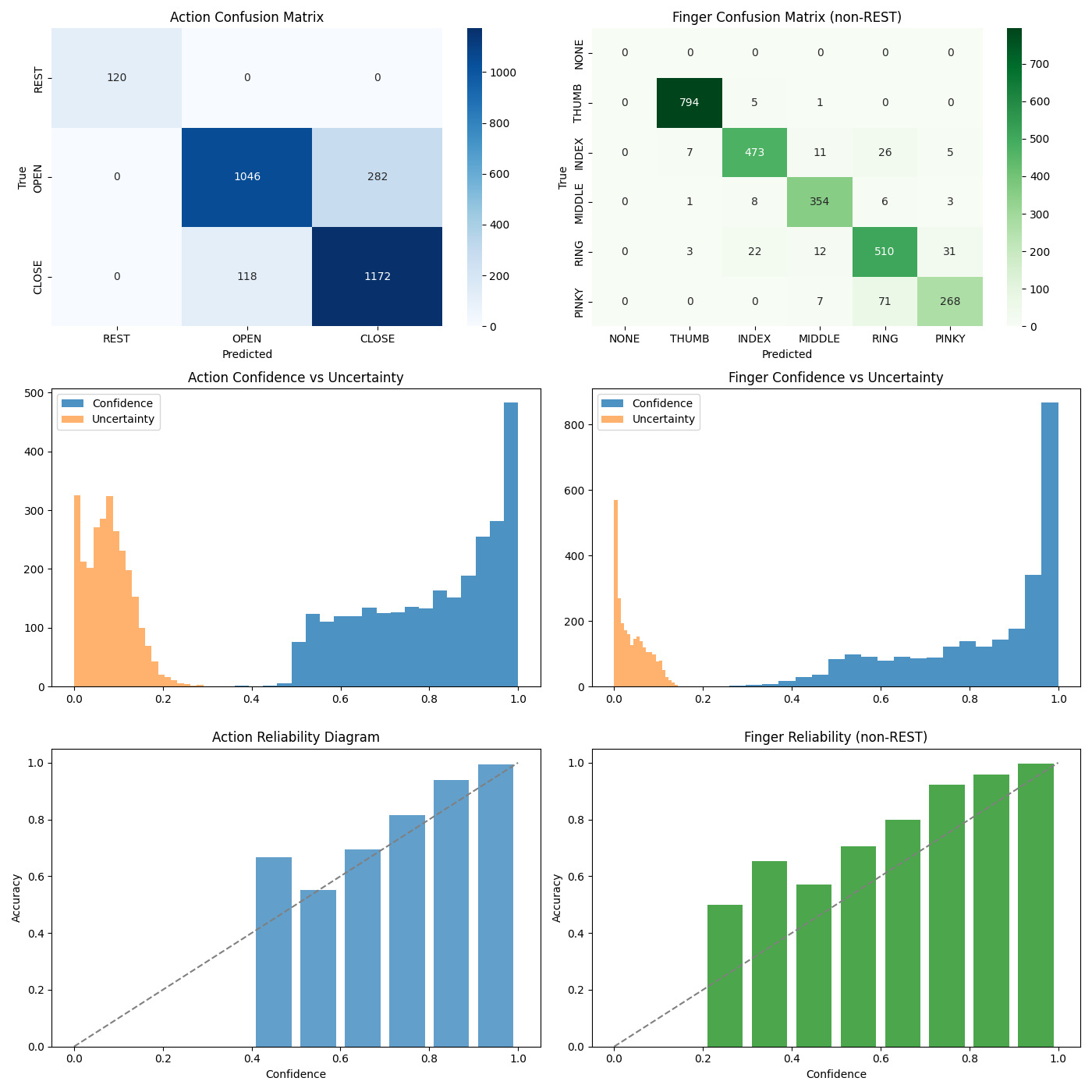
Holdout evaluation summary
The reference evaluation summary combines action and finger confusion matrices with reliability diagrams so accuracy and confidence can be read together.
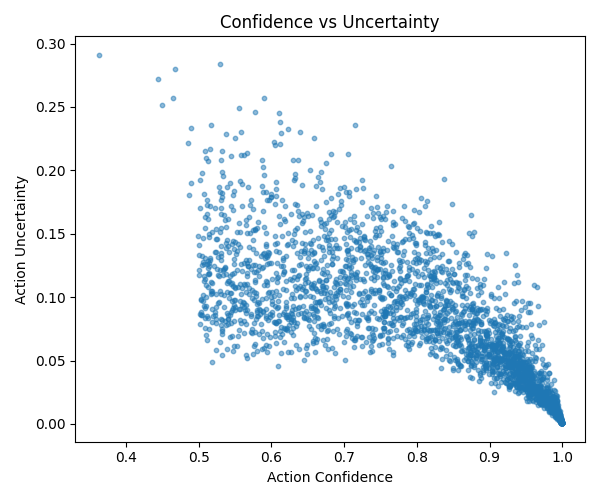
Confidence and uncertainty scatter
The uncertainty scatter shows where action predictions stay compact and where they begin to loosen. High-confidence, low-uncertainty regions are the most stable part of the decoding space.
Source trail
Follow the selection path
These links document how the project moved from broad tuning and ablation work to the current public run.